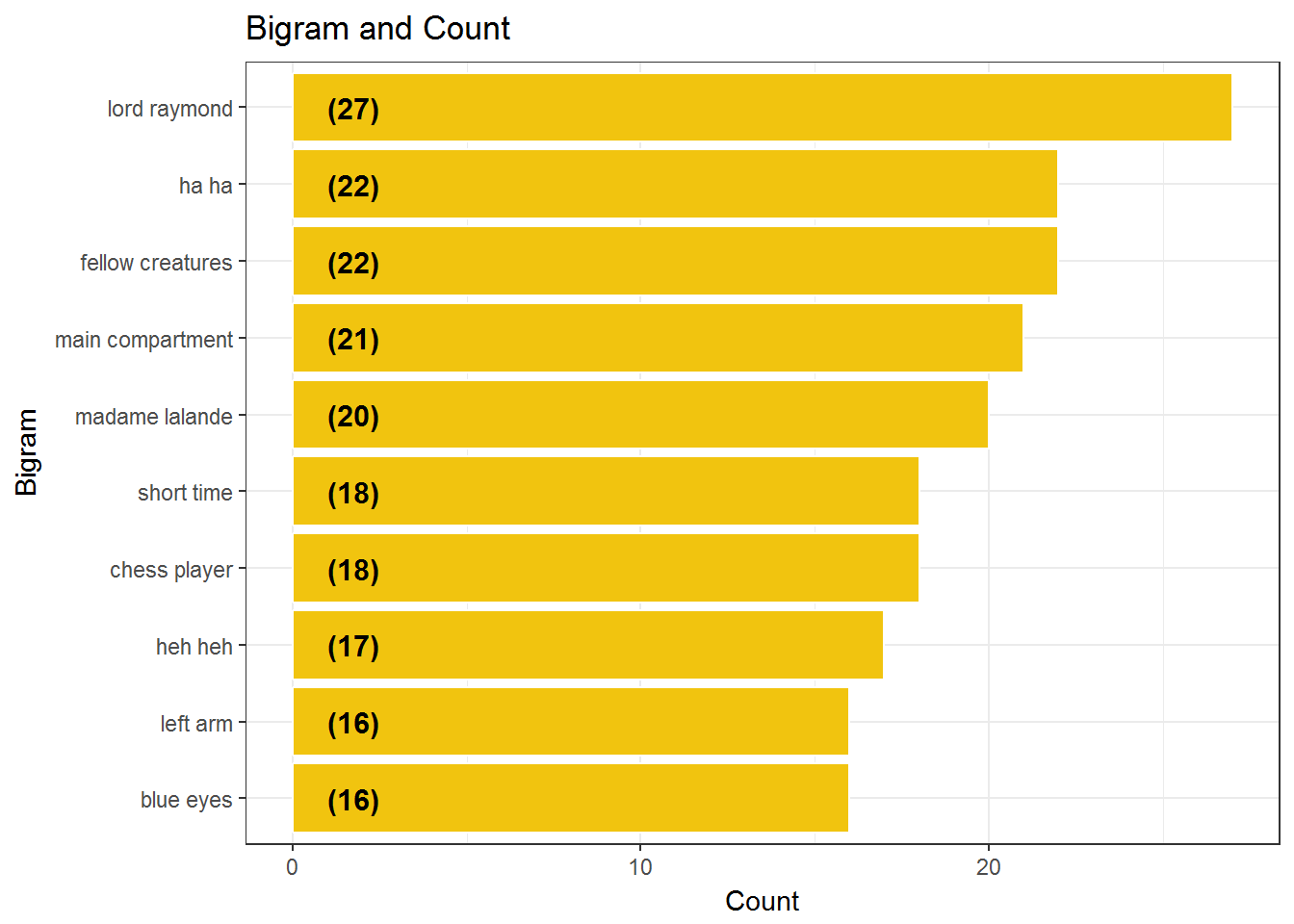
Chapter 10 Most Common Bigrams
A Bigram is a collection of Two words. We examine the most common Bigrams and plot them in a bar plot.
count_bigrams <- function(dataset) {
dataset %>%
unnest_tokens(bigram, text, token = "ngrams", n = 2) %>%
separate(bigram, c("word1", "word2"), sep = " ") %>%
filter(!word1 %in% stop_words$word,
!word2 %in% stop_words$word) %>%
count(word1, word2, sort = TRUE)
}
visualize_bigrams <- function(bigrams) {
set.seed(2016)
a <- grid::arrow(type = "closed", length = unit(.15, "inches"))
bigrams %>%
graph_from_data_frame() %>%
ggraph(layout = "fr") +
geom_edge_link(aes(edge_alpha = n), show.legend = FALSE, arrow = a) +
geom_node_point(color = "lightblue", size = 5) +
geom_node_text(aes(label = name), vjust = 1, hjust = 1) +
theme_void()
}
visualize_bigrams_individual <- function(bigrams) {
set.seed(2016)
a <- grid::arrow(type = "closed", length = unit(.15, "inches"))
bigrams %>%
graph_from_data_frame() %>%
ggraph(layout = "fr") +
geom_edge_link(aes(edge_alpha = n), show.legend = FALSE, arrow = a,end_cap = circle(.07, 'inches')) +
geom_node_point(color = "lightblue", size = 5) +
geom_node_text(aes(label = name), vjust = 1, hjust = 1) +
theme_void()
}
train %>%
unnest_tokens(bigram, text, token = "ngrams", n = 2) %>%
separate(bigram, c("word1", "word2"), sep = " ") %>%
filter(!word1 %in% stop_words$word,
!word2 %in% stop_words$word) %>%
unite(bigramWord, word1, word2, sep = " ") %>%
group_by(bigramWord) %>%
tally() %>%
ungroup() %>%
arrange(desc(n)) %>%
mutate(bigramWord = reorder(bigramWord,n)) %>%
head(10) %>%
ggplot(aes(x = bigramWord,y = n)) +
geom_bar(stat='identity',colour="white", fill = fillColor2) +
geom_text(aes(x = bigramWord, y = 1, label = paste0("(",n,")",sep="")),
hjust=0, vjust=.5, size = 4, colour = 'black',
fontface = 'bold') +
labs(x = 'Bigram',
y = 'Count',
title = 'Bigram and Count') +
coord_flip() +
theme_bw()