Chapter 18 He or She Analysis
We examine the words which start with he or she. This section draws inspiration from the blog post by David Robinson in his writeup
train %>%
unnest_tokens(bigram, text, token = "ngrams", n = 2) %>%
separate(bigram, c("word1", "word2"), sep = " ") %>%
filter(word1 %in% c("he", "she"))## # A tibble: 5,680 x 5
## id author len word1 word2
## <chr> <chr> <int> <chr> <chr>
## 1 id00004 EAP 134 he might
## 2 id00004 EAP 134 he necessarily
## 3 id00017 EAP 469 he makes
## 4 id00029 MWS 115 he entered
## 5 id00035 HPL 75 he was
## 6 id00036 HPL 201 he had
## 7 id00037 MWS 274 he owned
## 8 id00037 MWS 274 he the
## 9 id00043 HPL 167 he absorbed
## 10 id00045 MWS 237 he found
## # ... with 5,670 more rows18.1 Gender associated verbs
Which words were most shifted towards occurring after “he” or “she”? We’ll filter for words that appeared at least 20 times.
train %>%
unnest_tokens(bigram, text, token = "ngrams", n = 2) %>%
separate(bigram, c("word1", "word2"), sep = " ") %>%
filter(word1 %in% c("he", "she")) %>%
count(word1,word2) %>%
spread(word1, n, fill = 0) %>%
mutate(total = he + she,
he = (he + 1) / sum(he + 1),
she = (she + 1) / sum(she + 1),
log_ratio = log2(she / he),
abs_ratio = abs(log_ratio)) %>%
arrange(desc(log_ratio)) %>%
filter(!word2 %in% c("himself", "herself"),
!word2 %in% stop_words$word,
total>= 20) %>%
group_by(direction = ifelse(log_ratio > 0, 'More "she"', "More 'he'")) %>%
top_n(15, abs_ratio) %>%
ungroup() %>%
mutate(word2 = reorder(word2, log_ratio)) %>%
ggplot(aes(word2, log_ratio, fill = direction)) +
geom_col() +
coord_flip() +
labs(x = "",
y = 'Relative appearance after "she" compared to "he"',
fill = "",
title = "Gender associated with Verbs ") +
scale_y_continuous(labels = c("4X", "2X", "Same", "2X"),
breaks = seq(-2, 1)) +
guides(fill = guide_legend(reverse = TRUE)) +
theme_bw()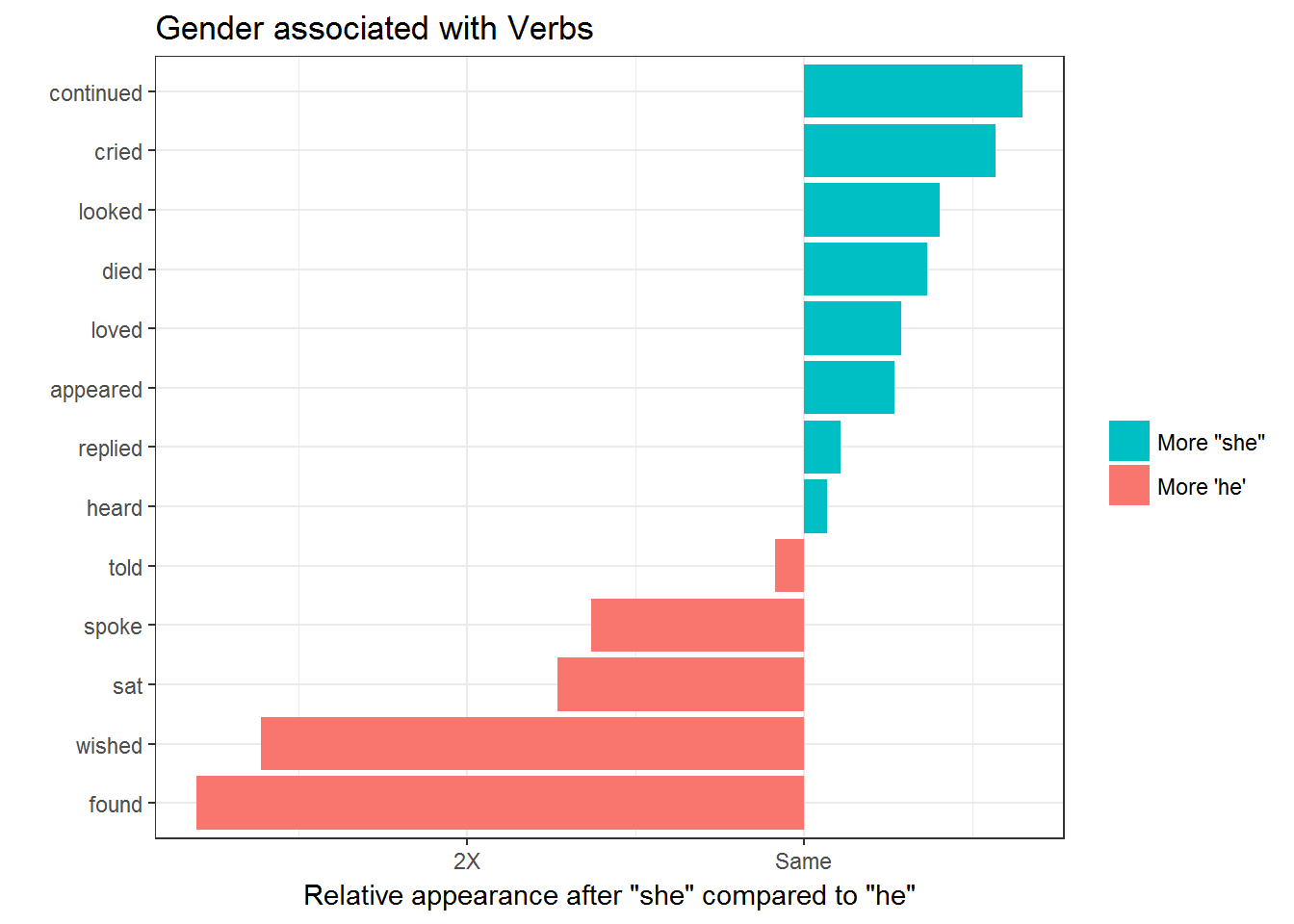
She cried , She loved , She died ,She heard is common while He told, He spoke, He sat, He wished , He found are common