Chapter 52 Modelling with XGBoost
We try to predict whether the ScriptLines are spoken by Homer or not
For ease of execution, we have taken only 5000 samples for the modelling Exercise.
We do Cross Validation using Caret package.
You can tune the parameters in your own machine for better results. The accuracy obtained through these parameters is quite good 0.7794007.
Lastly we wish to examine the feature importance of the variables. This is shown in the flipped bar chart.
ScriptsCharactersSample = ScriptsCharacters %>%
sample_n(5e3)
corpus = Corpus(VectorSource(ScriptsCharactersSample$normalized_text))
# Pre-process data
corpus <- tm_map(corpus, tolower)
corpus <- tm_map(corpus, removePunctuation)
corpus <- tm_map(corpus, removeWords, stopwords("english"))
corpus <- tm_map(corpus, stemDocument)
dtm = DocumentTermMatrix(corpus)
# Remove sparse terms
dtm = removeSparseTerms(dtm, 0.997)
# Create data frame
labeledTerms = as.data.frame(as.matrix(dtm))
ScriptsCharactersSample = ScriptsCharactersSample %>%
mutate(isHomer = 0)
ScriptsCharactersSample = ScriptsCharactersSample %>%
mutate(isHomer=replace(isHomer, name == 'Homer Simpson', 1)) %>%
as.data.frame()
labeledTerms$isHomer = as.factor(ScriptsCharactersSample$isHomer)
## Preparing the features for the XGBoost Model
features <- colnames(labeledTerms)
for (f in features) {
if ((class(labeledTerms[[f]])=="factor") || (class(labeledTerms[[f]])=="character")) {
levels <- unique(labeledTerms[[f]])
labeledTerms[[f]] <- as.numeric(factor(labeledTerms[[f]], levels=levels))
}
}
## Creating the XGBoost Model
labeledTerms$isHomer = as.factor(labeledTerms$isHomer)
formula = isHomer ~ .
fitControl <- trainControl(method="cv",number = 3)
xgbGrid <- expand.grid(nrounds = 10,
max_depth = 3,
eta = .05,
gamma = 0,
colsample_bytree = .8,
min_child_weight = 1,
subsample = 1)
set.seed(13)
HomerXGB = train(formula, data = labeledTerms,
method = "xgbTree",trControl = fitControl,
tuneGrid = xgbGrid,na.action = na.pass)
importance = varImp(HomerXGB)
varImportance <- data.frame(Variables = row.names(importance[[1]]),
Importance = round(importance[[1]]$Overall,2))
# Create a rank variable based on importance
rankImportance <- varImportance %>%
mutate(Rank = paste0('#',dense_rank(desc(Importance)))) %>%
head(20)
rankImportancefull = rankImportance
ggplot(rankImportance, aes(x = reorder(Variables, Importance),
y = Importance)) +
geom_bar(stat='identity',colour="white", fill = fillColor) +
geom_text(aes(x = Variables, y = 1, label = Rank),
hjust=0, vjust=.5, size = 4, colour = 'black',
fontface = 'bold') +
labs(x = 'Variables', title = 'Relative Variable Importance') +
coord_flip() +
theme_bw()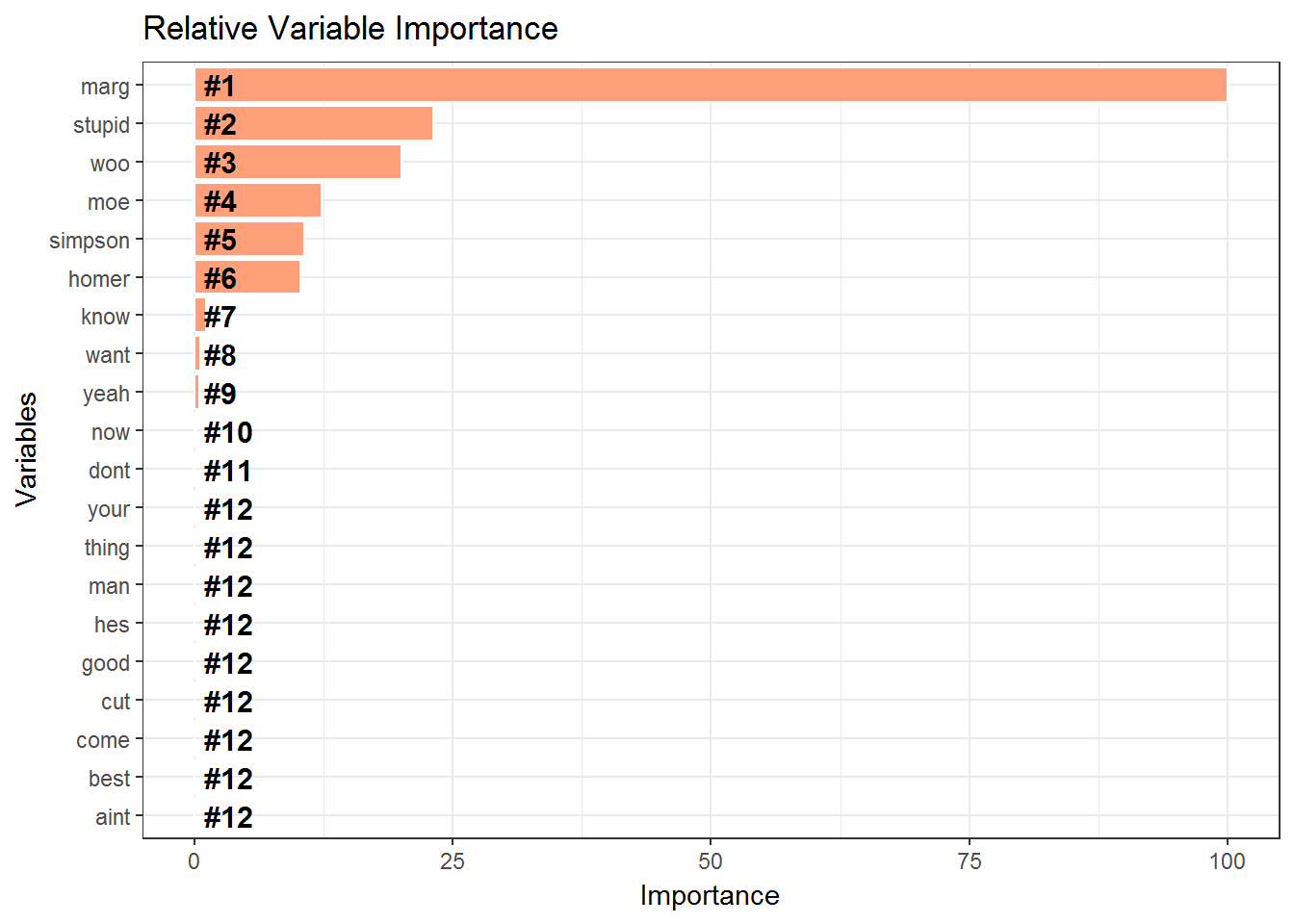
All the factors affecting the decision whether the ScriptLines are spoken by Homer or not along with their ranks is provided below
| Variables | Importance | Rank |
|---|---|---|
| marg | 100.00 | #1 |
| stupid | 23.17 | #2 |
| woo | 20.08 | #3 |
| moe | 12.32 | #4 |
| simpson | 10.67 | #5 |
| homer | 10.25 | #6 |
| know | 1.13 | #7 |
| want | 0.57 | #8 |
| yeah | 0.54 | #9 |
| now | 0.26 | #10 |
| dont | 0.07 | #11 |
| cut | 0.00 | #12 |
| aint | 0.00 | #12 |
| best | 0.00 | #12 |
| come | 0.00 | #12 |
| thing | 0.00 | #12 |
| your | 0.00 | #12 |
| good | 0.00 | #12 |
| hes | 0.00 | #12 |
| man | 0.00 | #12 |