Recommendation engine using Text data ,Cosine Similarity and word embeddings technique

What are we trying to do
We will build a very simple recommendation engine using Text Data. To demostrate this we would use a case study approach and build a recommendation engine for a non profit organization Career Village.
CareerVillage.org is a nonprofit that crowdsources career advice for underserved youth. Founded in 2011 in four classrooms in New York City, the platform has now served career advice from 25,000 volunteer professionals to over 3.5M online learners. The platform uses a Q&A style similar to StackOverflow or Quora to provide students with answers to any question about any career.
The U.S. has almost 500 students for every guidance counselor. Underserved youth lack the network to find their career role models, making CareerVillage.org the only option for millions of young people in America and around the globe with nowhere else to turn.
To date, 25,000 volunteers have created profiles and opted in to receive emails when a career question is a good fit for them. To help students get the advice they need, the team at CareerVillage.org needs to be able to send the right questions to the right volunteers. The notifications sent to volunteers seem to have the greatest impact on how many questions are answered.
We will use the following
- Questions asked by the students
- Answers provided by the professionals and the professionals details
When a student asks a question, we would find similar questions which have been answered. Then we would connect the student question with the professional so that the professional can ask the question. In this blog post, we would explain the detailed strategy of finding similar questions.
Main Steps
The main steps are as follows:
- The questions have body and title. We make a consolidated column combining body and the title .
- We make use of word embeddings to create a vector for the questions text.
- We calculate the cosine similarity between the question asked and the consolidated list of questions. This would enable us select the top ten similarities and recommend the question to the professionals who have answered it.
Concepts
Word embeddings
From the TensorFlow documentation word embeddings documentation
Word embeddings give us a way to use an efficient, dense representation in which similar words have a similar encoding. Importantly, you do not have to specify this encoding by hand. An embedding is a dense vector of floating point values (the length of the vector is a parameter you specify). Instead of specifying the values for the embedding manually, they are trainable parameters (weights learned by the model during training, in the same way a model learns weights for a dense layer). It is common to see word embeddings that are 8-dimensional (for small datasets), up to 1024-dimensions when working with large datasets. A higher dimensional embedding can capture fine-grained relationships between words, but takes more data to learn.
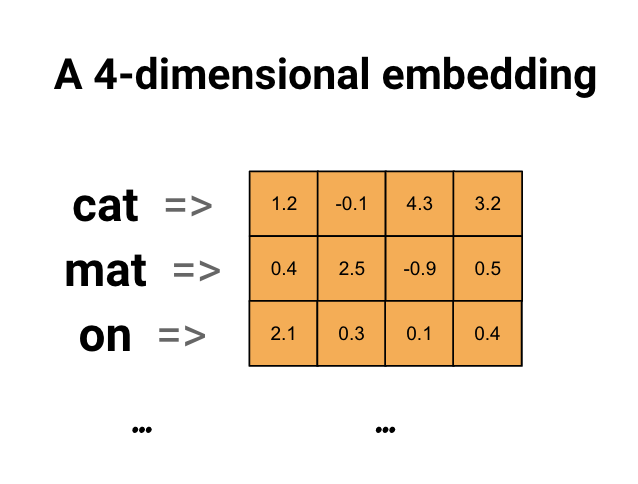
Above is a diagram for a word embedding. Each word is represented as a 4-dimensional vector of floating point values. Another way to think of an embedding is as “lookup table”. After these weights have been learned, you can encode each word by looking up the dense vector it corresponds to in the table.
Cosine similarity
If we have 2 vectors A and B, cosine similarity is the cosine of the angle between them. If A and B are very similar, the value is closer to 1 and if they are very dissimilar, the value is closer to zero.
Here we represent the question as vectors. The values of the vector is the tfidf value of the various words in the question text.
Data
The data can be found in Kaggle in the following link Career Village
Implementation details
Steps:
- Get the questions data , answers data and the professionals data
- Create the consolidated dataset which has the questions, answers and the professionals dataset for each question
- Create a consolidated column of text data composed of the question body and question title
- Create a word embeddings vector for each of the question text. Each word is represented by a 1 x 300 dimensional vector. A question vector is the average of all the word vectors, This is accomplished by spacy which is an industrial strength
- Create the cosine similarity matrix of the question asked and the questions answered
- Display the highest similarity questions and their answers
Step 1 - questions data , answers data and the professionals data
import gc
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import re
import xml
import spacy
from sklearn.metrics.pairwise import cosine_similarity
import string
import pickle
questions = pd.read_csv("../input/questions.csv")
professionals = pd.read_csv("../input/professionals.csv")
answers = pd.read_csv("../input/answers.csv")
Step 2 - Create the consolidated dataset which has the questions, answers and the professionals dataset for each question
We only include the questions which have been answered by the professionals
prof_ans = pd.merge(professionals, answers, how = 'left' ,
left_on = 'professionals_id', right_on = 'answers_author_id')
prof_ans_q = pd.merge(prof_ans, questions, how = 'left' ,
left_on = 'answers_question_id', right_on = 'questions_id')
prof_ans_q = prof_ans_q[(~prof_ans_q["questions_title"].isna()) | (~prof_ans_q["questions_body"].isna()) ]
Step 3 - Create a consolidated column of text data composed of the question body and question title
def clean_text(text):
'''Make text lowercase,remove punctuation
.'''
text = str(text).lower()
text = re.sub('[%s]' % re.escape(string.punctuation), '', text)
text = re.sub('\n', '', text)
return text
q = prof_ans_q["questions_title"] + " " + prof_ans_q["questions_body"]
q = q.apply(lambda x:clean_text(x))
Step 4 - Create a Word embeddings vector
spaCy provides embeddings learned from a model called Word2Vec. We can access them by loading a large language model like en_core_web_lg. Then they will be available on tokens from the .vector attribute.
nlp = spacy.load('en_core_web_lg')
with nlp.disable_pipes():
spacy_questions = [nlp(q1).vector for q1 in q ]
Step 5 -Create the cosine similarity matrix of the question asked and the questions answered
Get the question asked by the student. For example , the student asks the question
“I want to be a data scientist. What should I study”
q_new = "I want to be a data scientist. What should I study"
q_new = [q_new]
with nlp.disable_pipes():
q_new = [nlp(q_new).vector]
result = cosine_similarity(q_new,spacy_questions)
Step 6 - Get the best answers
We show the 3 best answers for the questions which have the highest cosine similarity. If we go through the answers, we see that they are very good advice and pertains well to the asked question
prof_ans_q.iloc[result.argmax()]["answers_body"]
‘ Hello Chong G. I am not a data scientist, but I think I can give you some advice on this. Nowadays, an increasing number of professions are requiring analytics capabilities. There are some core things you should learn to handle great amount of data, like: Relational Database concepts;SQL - Computer language for creating and managing databases;Excel;Programing languages such as C, VBA, R… You should also consider learning how to display the data in an organized way and Power BI / Think-Cell are great for that There are several tutorials around the internet about those topics and also focused courses. I personally recommend the latter, because it is easier to progress through the topics.Hope my advice was helpful to you! ’
2nd best answer
‘You should search for Algorithm videos. Usually when studying data, you would need to know about databases structure, analytics skills, and some other logics. Another thing you could do would be start analyzing some small real cases like how long does it take to go from your house to the supermarket and what you could do to reduce the time? or how often do you drink water (time gap between each occurence). How could you track that? and how could you improve it? is it good?these are a few examples on how you could analyze stuff.’
3rd best answer
“Hi Yingyi,Great question and excited to see you’re interested in Data Science. Data Science is a not really a unified field and a bit buzzwordy. Data scientist come from all sorts of backgrounds (computer science, political science, physics, statistics, even Creative Writing [me!]) and work on all sorts of problems. One one hand you’ll may have a data scientists working with advertisement data trying to predict target audiences and click through rates and on the other a data scientist using deep learning to analyze MRI scans for cancerous tumors. And all sorts of things in between. In my role as a Data Scientist at Talla, I research machine learning and deep learning technique to solve natural language problems like teaching a computer to read text, answer questions, and classify large corpuses of data. You shouldn’t worry about not having a Data Science major, your double major cover the majority of the baseline knowledge you’ll need. Here’s a few classes you should take to help with building skills fundamental to most data science work:Intro to Probability and StatisticsLinear Algebra Data Structures and Algorithms Python Data Visualization Introduction to Causal Inference Advanced (chose which one(s) look the most interesting) Machine LearningDeep Learning with Neural Networks Natural Language ProcessingComputer Vision The best way to get a sense of what it’s like to be data scientist is doing data science. A great resource for this is Kaggle and DrivenData. Both host open competitions and challenges that anyone can participate in. You should look through the challenges, see which look interesting, download the data, and start building models. Kaggle has a great set tutorials as well that well teach you the basic skills on working with data, looking for patterns and building models. The great thing is you don’t need a college degree, just jump in. The more hands on experience you get working with data, the better. Closely related to that point is document and share the data science work you do. It will be very useful to show potential employers a portfolio of your work where you can point to specific examples of the tools, techniques and analysis you did. You can store code samples in github and write blog posts on Medium to highlight cool findings. On internships, it honestly depends on where you are located. I’d recommend talking to your school’s career center for help here. Another piece of advice. Go on LinkedIn and look for data scientist in your area and reach out to them. Say you are a student, and ask if they have time for a phone call or coffee for questions. Professionals in general like providing advice and helping out students. So feel free to ask about what they do, things they’d learned, and any advice they have. At the end of the conversation you might also want to ask if there are any internship opportunities and if they can recommend you. And finally in terms of general advice, study abroad if you have chance! Take some humanities and social science classes. Especially ethics, philosophy, and social or political science. Our technologies have far outpaced social norms and policies. As a data scientist you may find yourself working on human data (customers, patients, and other categories of people) and your models will have repercussions on real lives. It’s important to the general welfare of society to be cognizant about the potential unintended consequences and implications of your work. Hope this was helpful. Feel free to reach out to me directly if you have questions about Data Science or post here for more advice. Good luck!”
Based on these answers, we can recommend the question to the professionals who have answered these highest similarity questions.
Conclusion
We have demostrated that a simple recommendation technique can be built using Text Data , word embeddings and Cosine similarity in the Career Village case study. We can easily extend this same technique to other text based case studies for several use cases such as recommendations for answers in a call center , recommendations for donors who have donated for a social cause in charity organizations